抓包
先config 获取信息 再get拿到验证码和order
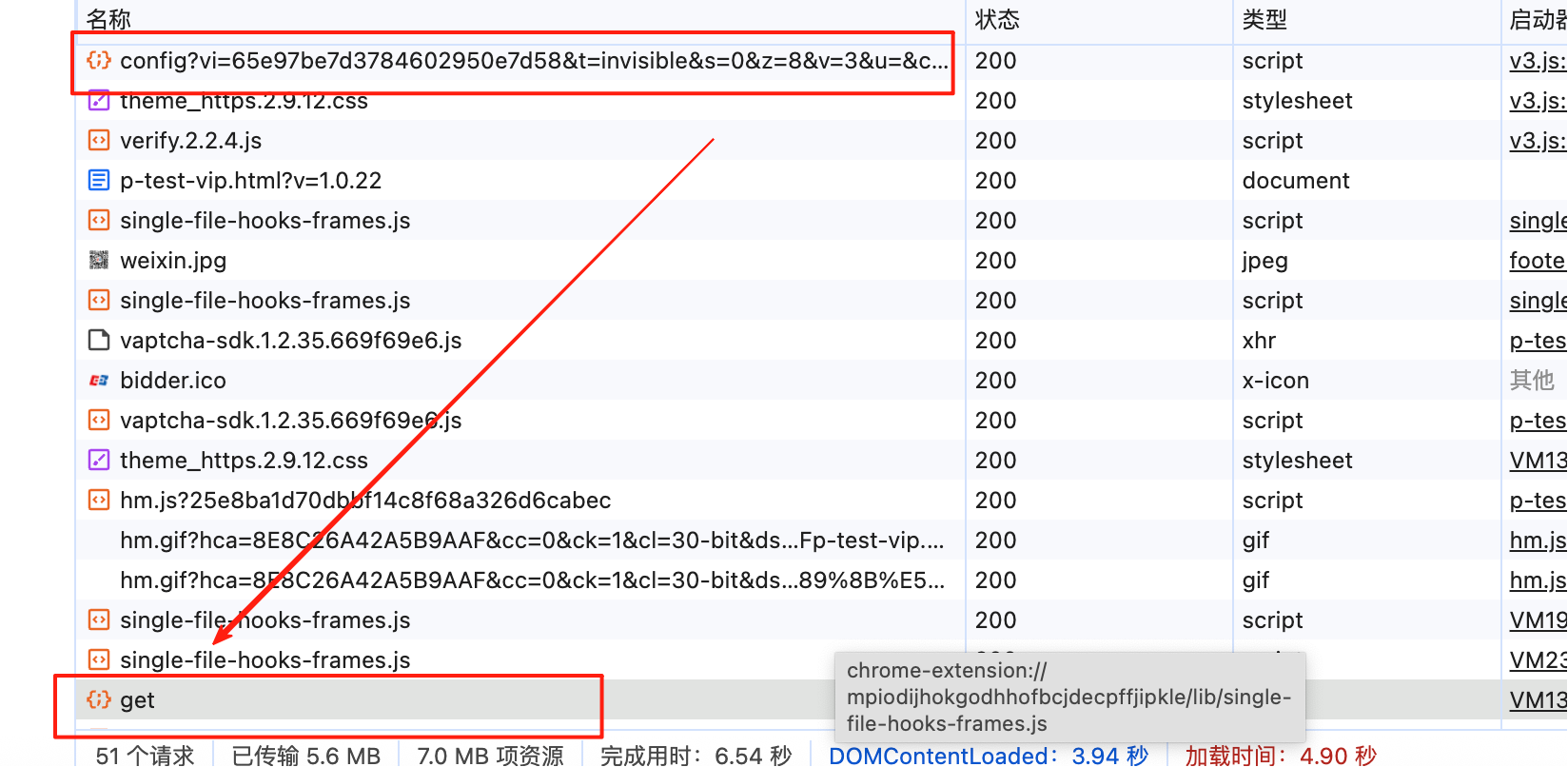
如下图 配置如下
vi: 固定
k:返回值
en: 加密值
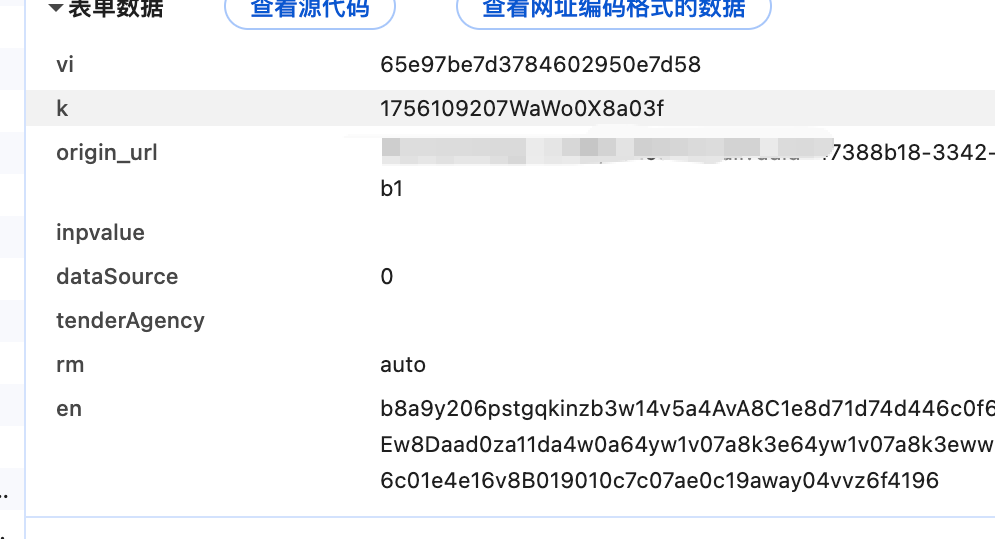
分析
get请求
n 生成出如下
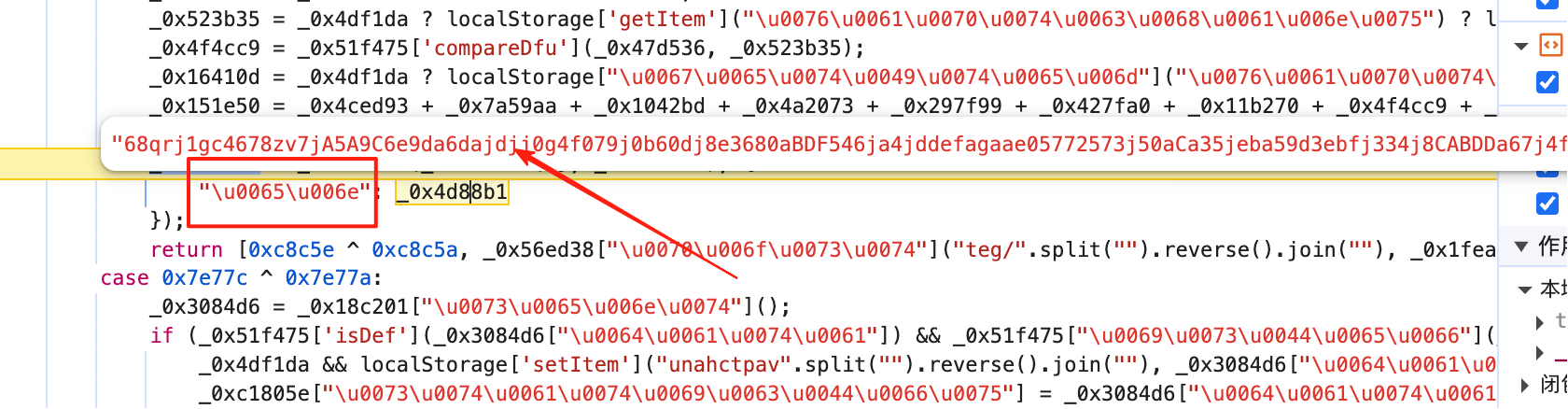
第一个en 随便扣扣 就扣出来了。
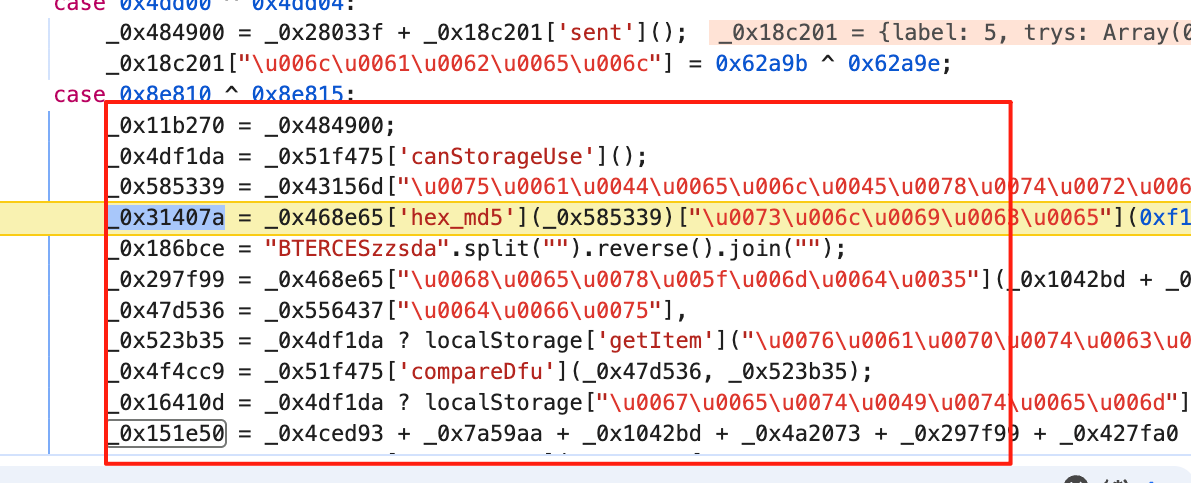
然后把比较重要的component拿出来
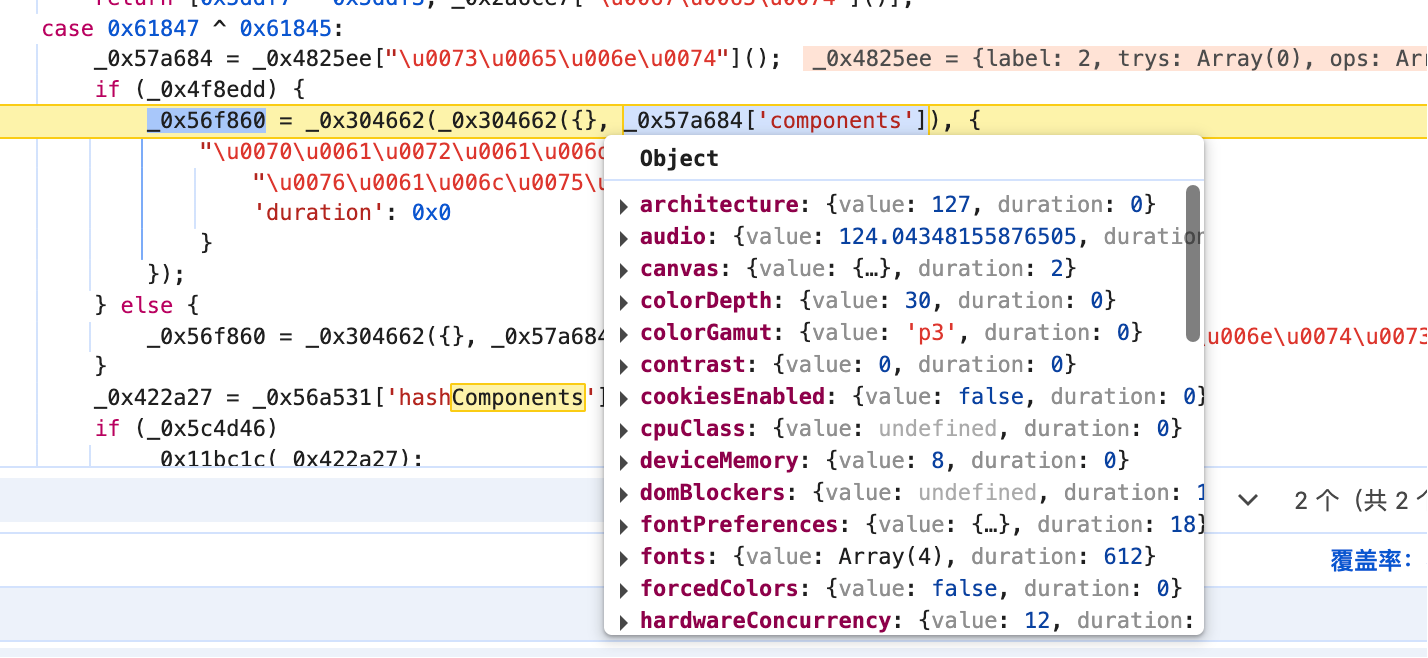
然后抠出来 请求就可以了。中间会遇到很多坑。
其中指纹需要复制。
底图还原
这里请求完之后会获取到图片信息和 图片的order
但是这个order不是直接还原的order。还需要去js中找到加密的地方。
(这里为了保持代码一致。我扣下来一版 来找对应位置。所以有些值和网页会有所对应不上)
还原位置如下:
搜索关键词:imageOnload 或者 Decrypt
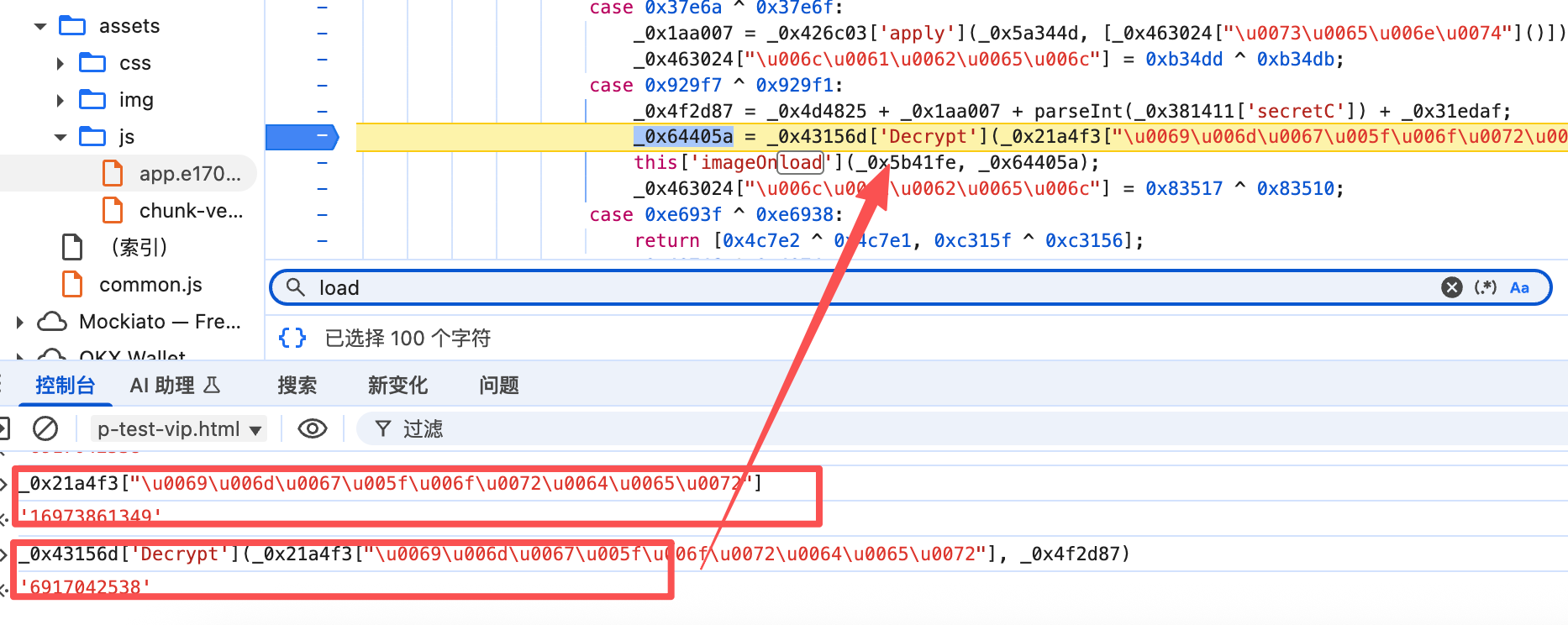
这里就直接硬扣就完事了。
Decrypt的算法逻辑如下
1
2
3
4
5
6
7
8
| function _0xb05afc(_0x2b9119, _0x1f3614) {
var _0x431184 = "";
_0x431184 = (parseInt(_0x2b9119) - _0x1f3614).toString();
if (_0x431184.length < (983293 ^ 983287)) {
_0x431184 = "0" + _0x431184;
}
return _0x431184;
}
|
稍微麻烦的也就是传参的这个
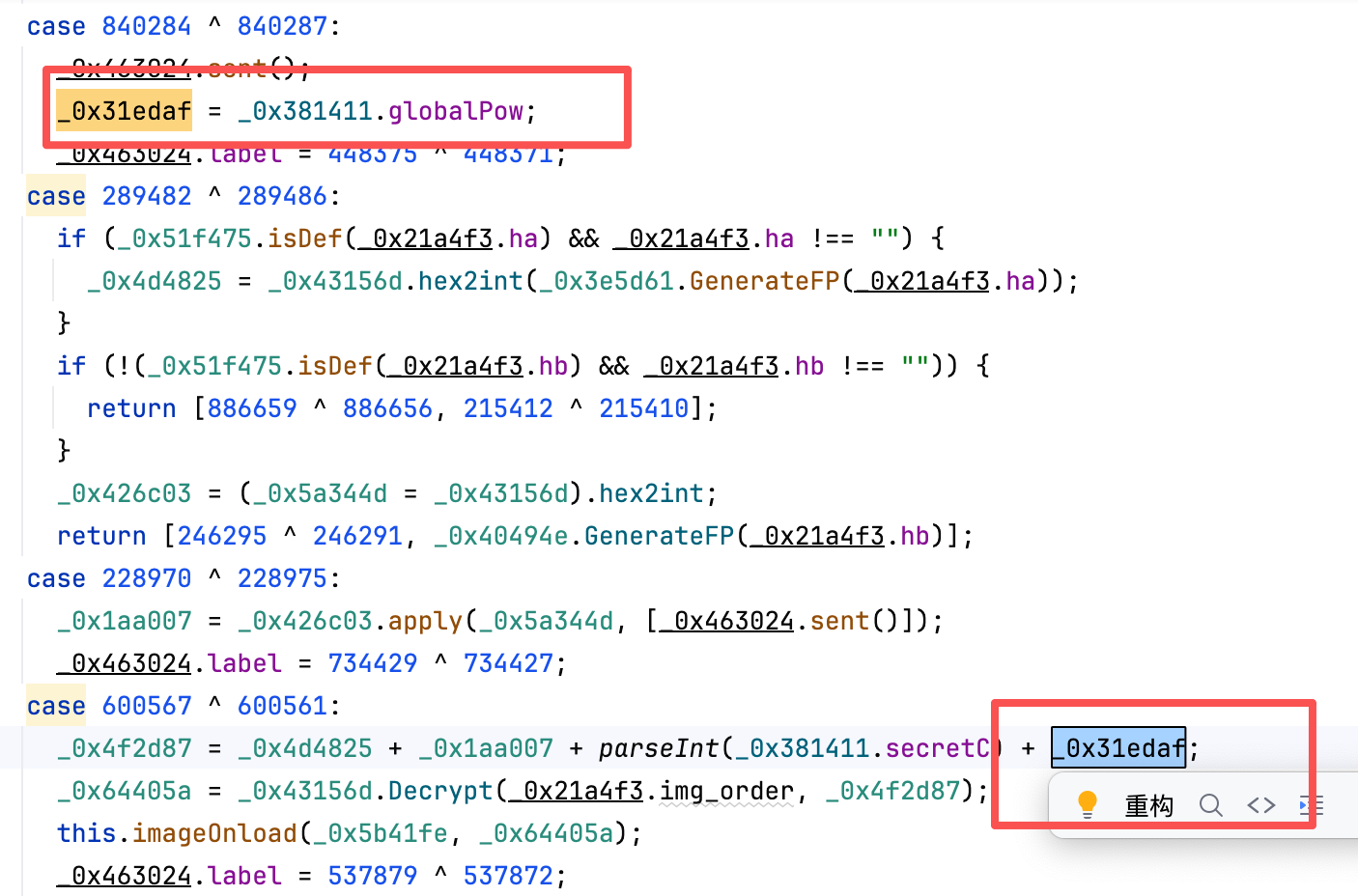
算法还原
拿到底图链接 即重新拼接成一个完整图片
算法如下;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| def process_image(order: str, image_url: str, output_path: str = "image.png"):
CANVAS_WIDTH, CANVAS_HEIGHT = 290, 167
SOURCE_WIDTH, SOURCE_HEIGHT = 400, 230
if not (len(order) == 10 and order.isdigit()):
print("错误:排序字符串必须为10位数字")
return False
response = requests.get(image_url, timeout=10)
source_image = Image.open(io.BytesIO(response.content))
target_canvas = Image.new('RGB', (CANVAS_WIDTH, CANVAS_HEIGHT), 'white')
canvas_block_w, canvas_block_h = CANVAS_WIDTH // 5, CANVAS_HEIGHT // 2
source_block_w, source_block_h = SOURCE_WIDTH // 5, SOURCE_HEIGHT // 2
for i in range(10):
source_x, source_y = (i % 5) * source_block_w, (i // 5) * source_block_h
pos = int(order[i])
target_x, target_y = (pos % 5) * canvas_block_w, (pos // 5) * canvas_block_h
block = source_image.crop((source_x, source_y, source_x + source_block_w, source_y + source_block_h))
resized_block = block.resize((canvas_block_w, canvas_block_h), Image.Resampling.LANCZOS)
target_canvas.paste(resized_block, (target_x, target_y))
target_canvas.save(output_path, 'PNG')
print(f"图像已保存为 {output_path}")
|
validate
validate的请求中的en
定位点如下图所示
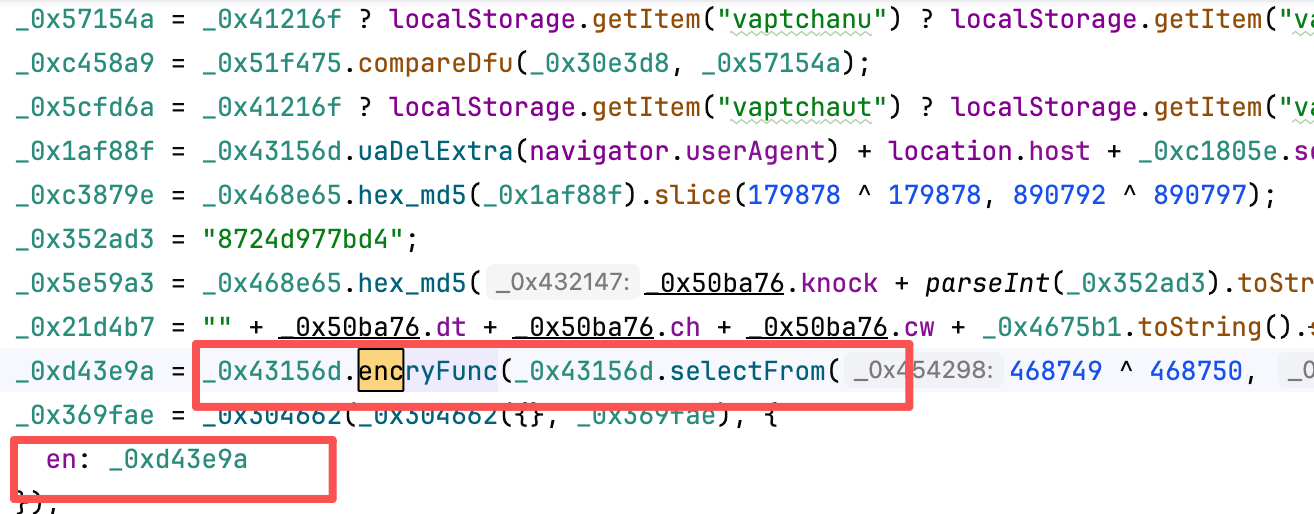
其实这里算法都和你简单随便扣扣就出来了。
传参这里看看。

v: 轨迹
vi:固定值 和uk差不多
k:接口返回
dt: 滑动时间
ch:heigh 图片高度
cw:width 图片宽度
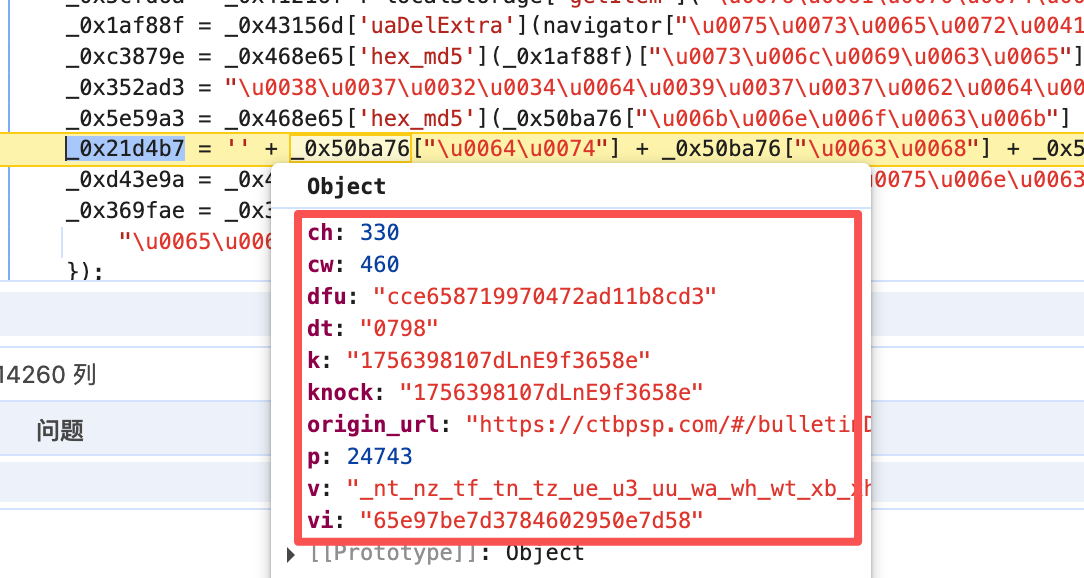
补充说明:具体值demo如上
难点与坑
这里讲完流程大概讲下难点
en有个UA头 前后要保持一致 如下图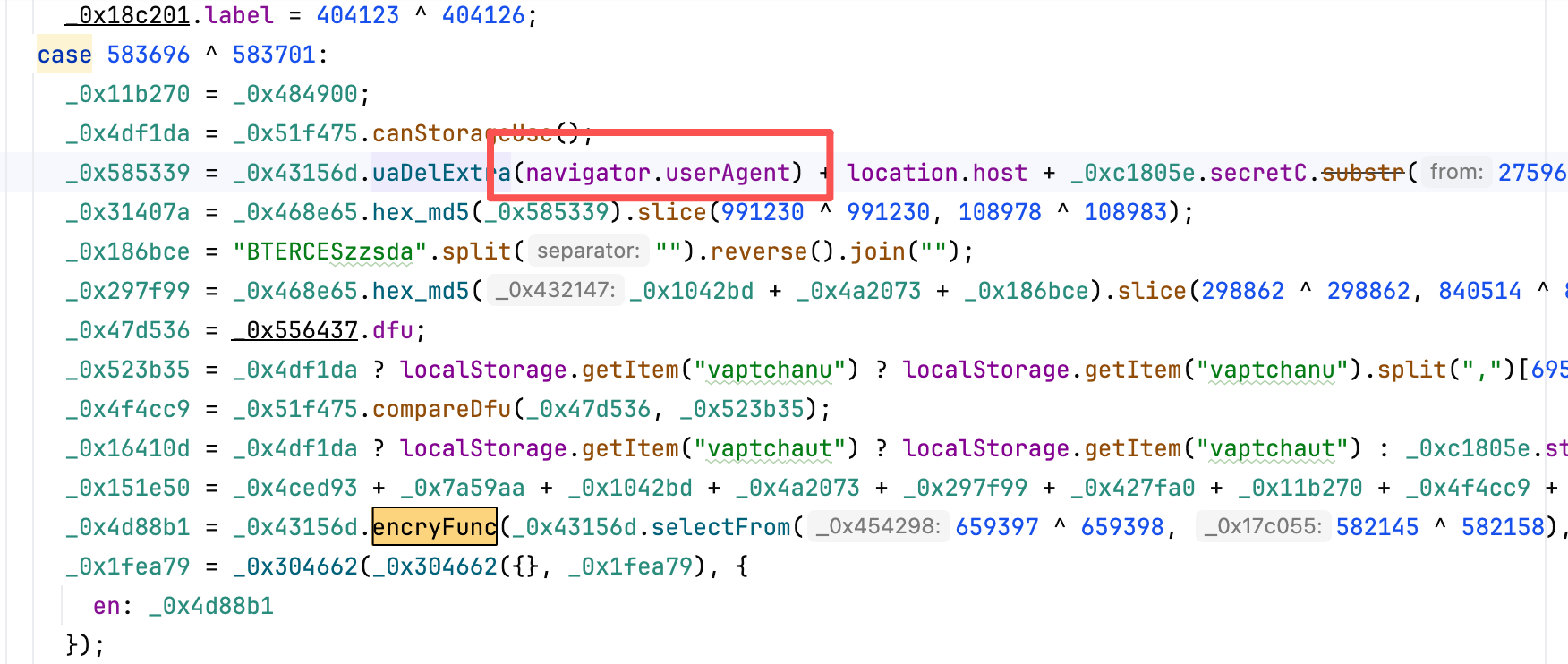
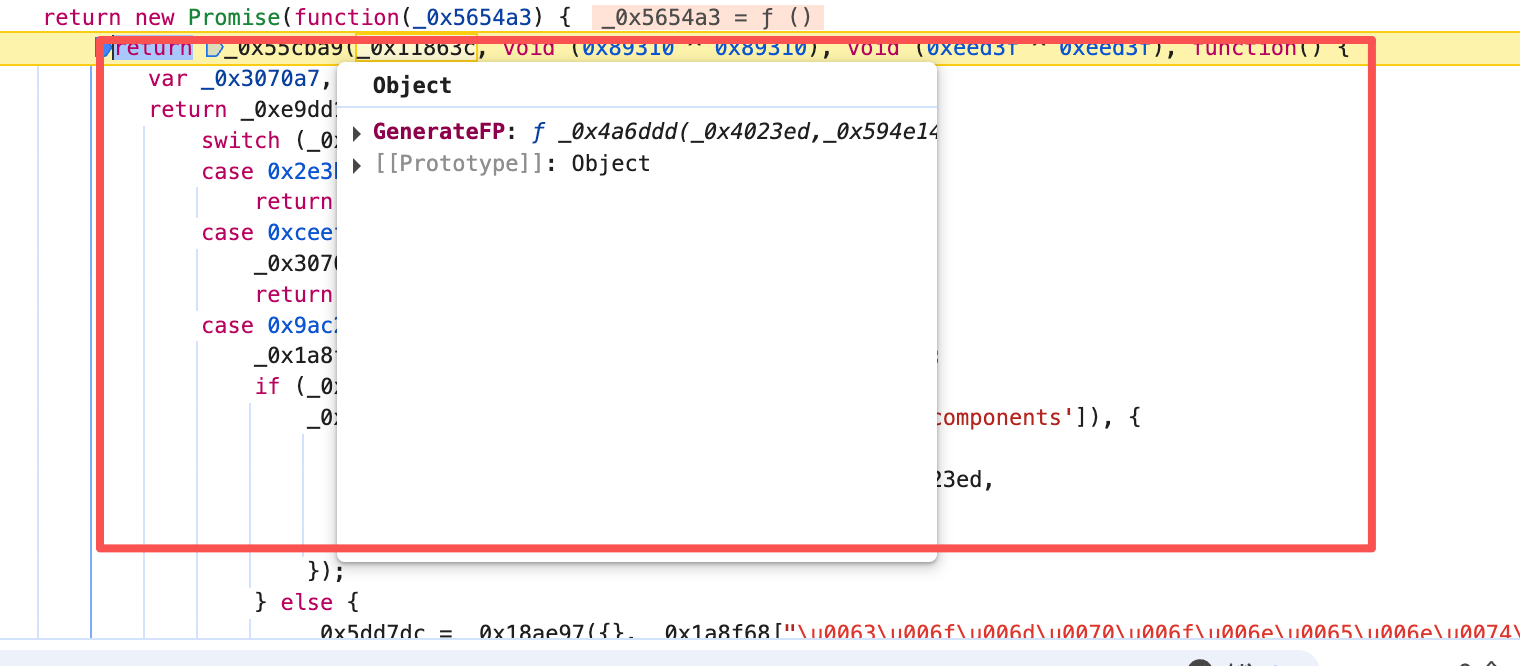
GenerateFP。下图其实这里就是运用了 JavaScript 生成器 的特性。.sent 就是接受了上一步吐出来的值。
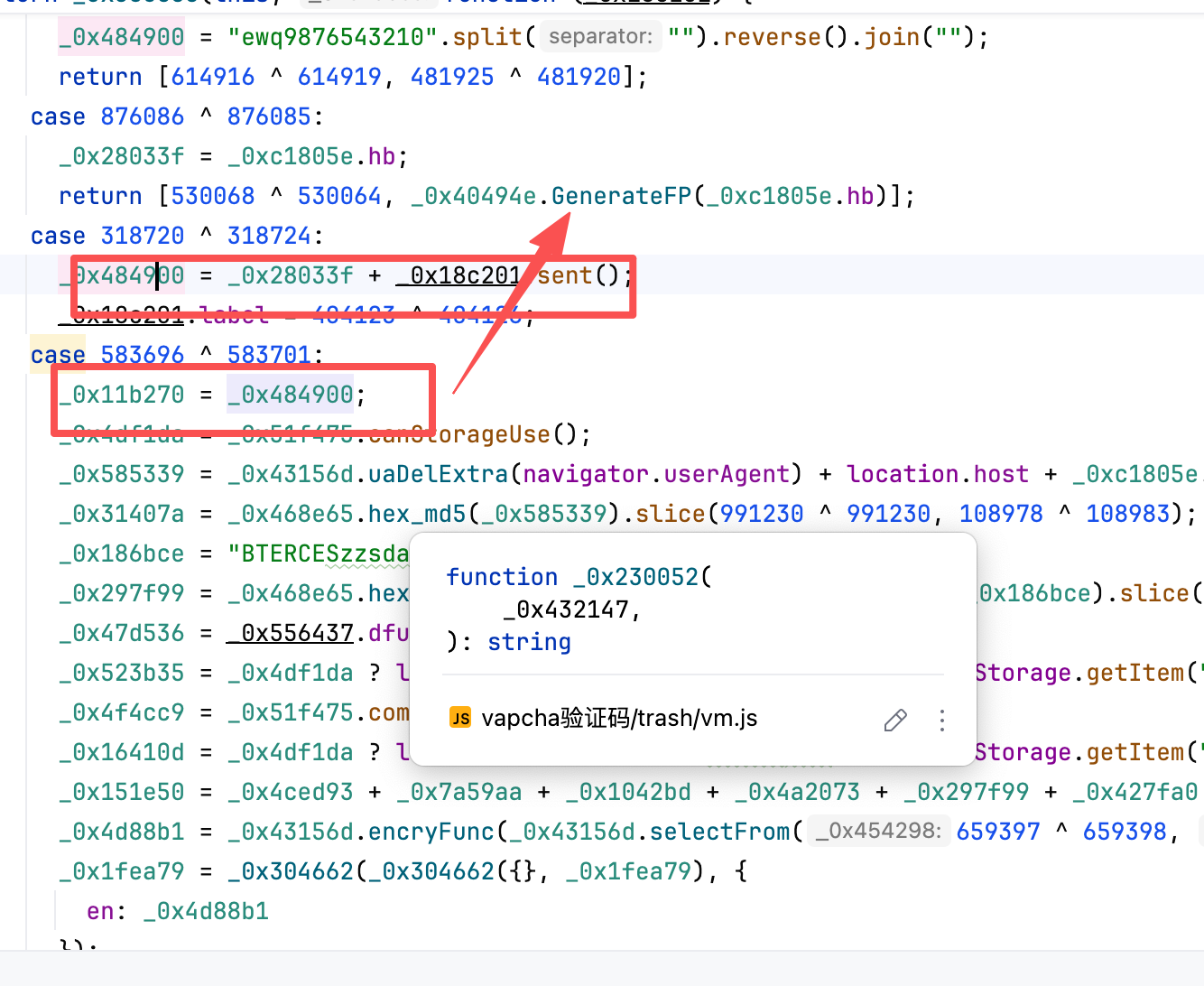
这里有个异步方法 其实。只需要看他返回值 然后扣下来或者给AI就可以了。
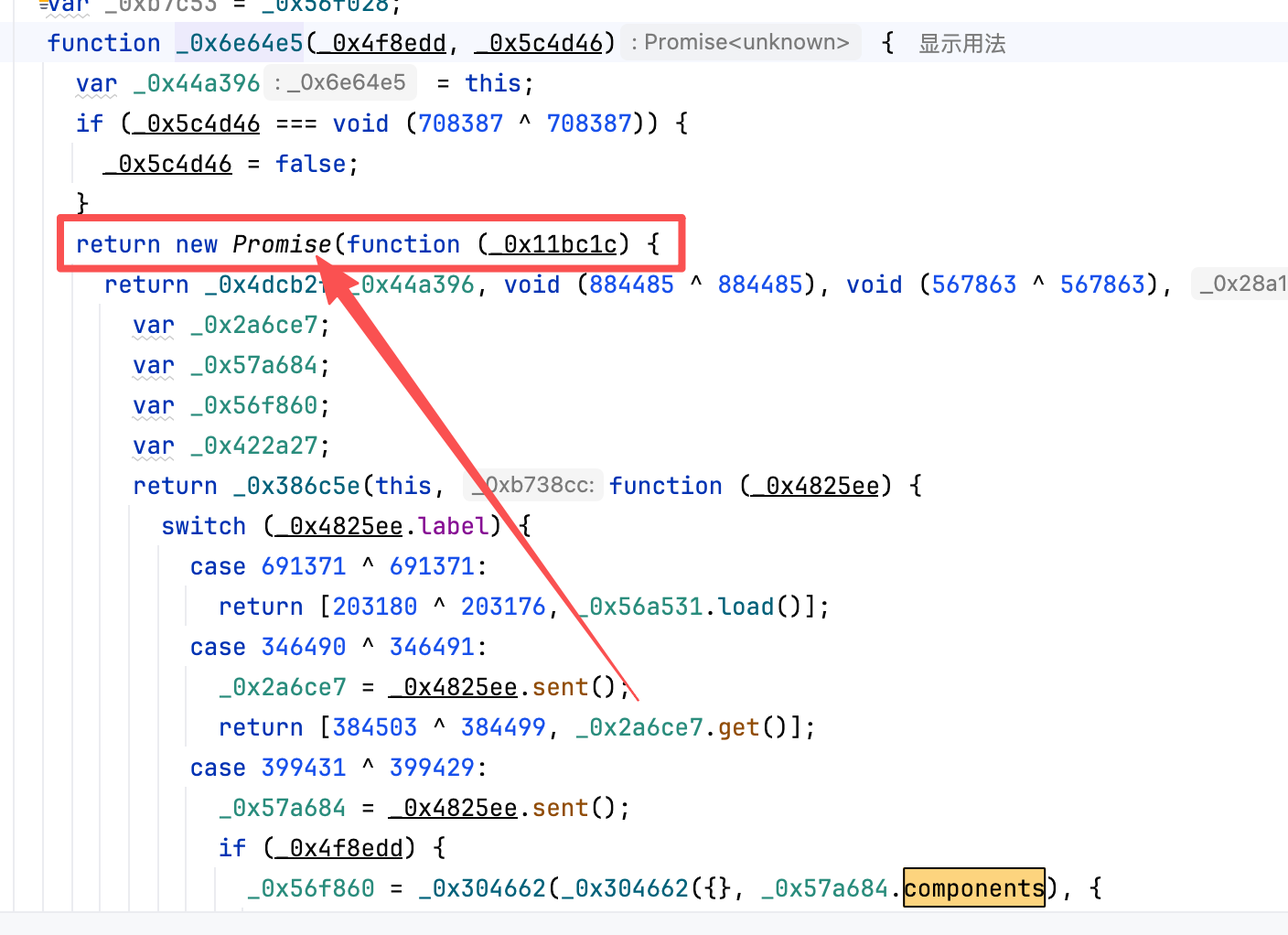
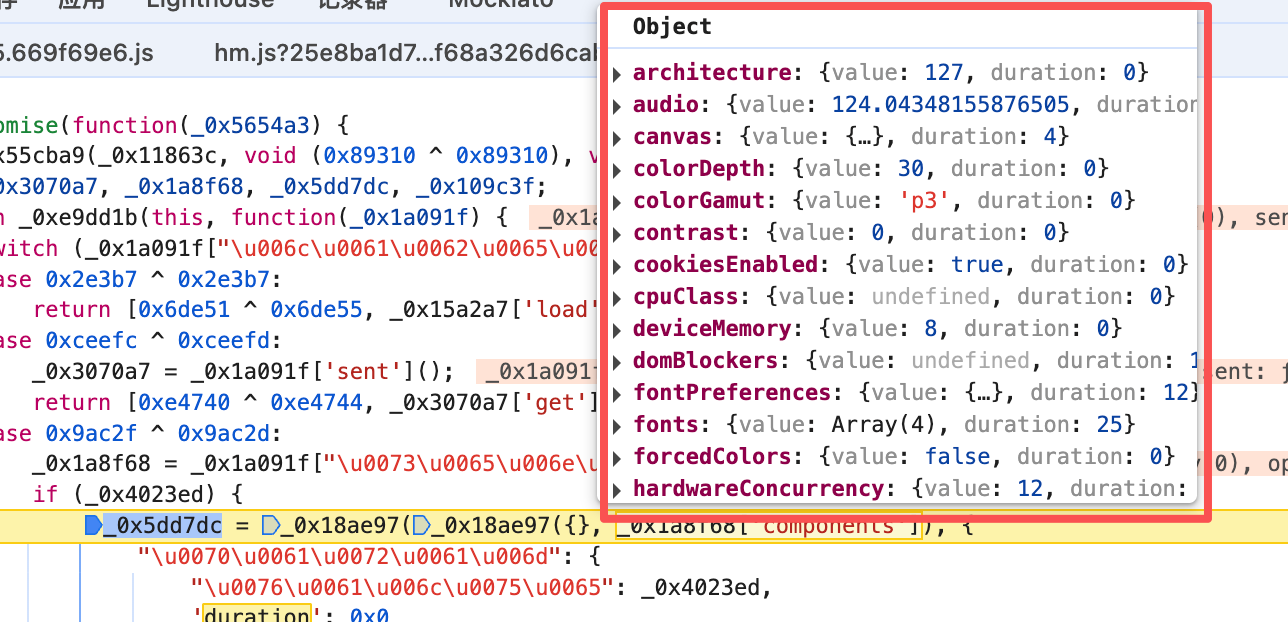
当然 这里还有个环境指纹 直接copy下来就好了。
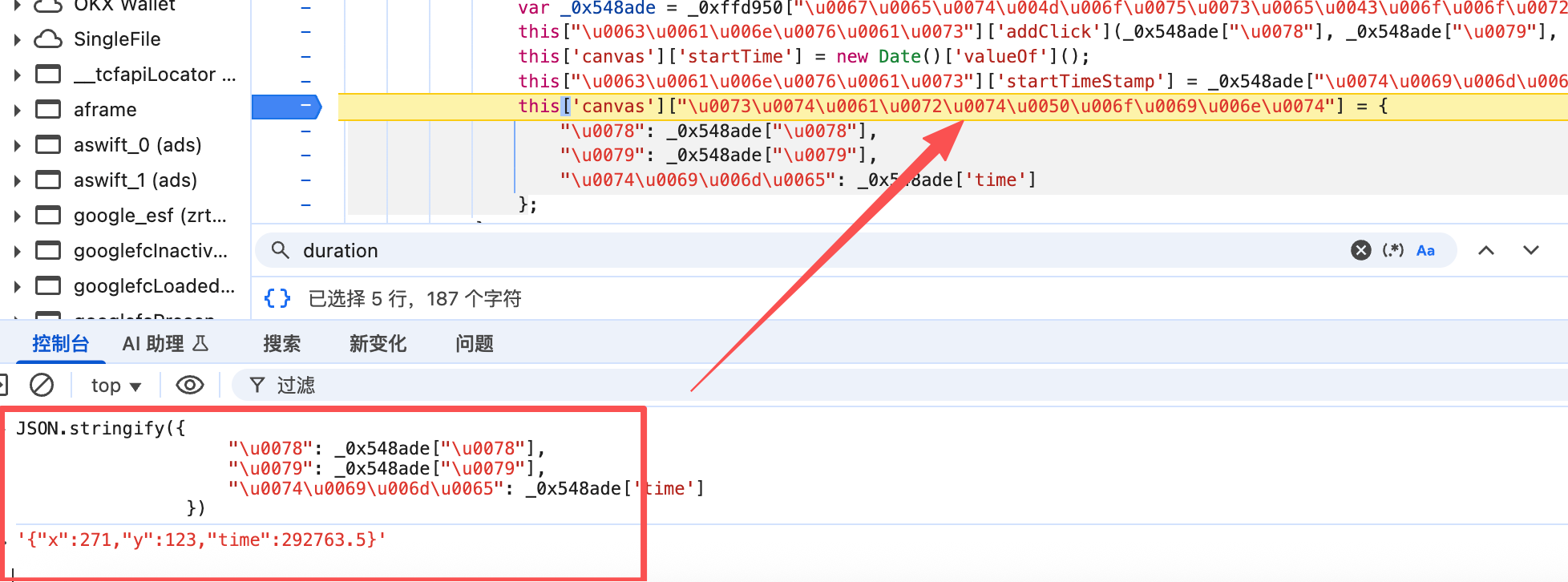
轨迹
这里不应该是坑点。这里打个鼠标断点就能找到轨迹生成的地方。可以对着分析 但是没屌用。具体我也没研究明白。
结果
结果就是我也没搞出来。demo站倒是比较松。这个真应用起来好像是划得来不太准就会一直错。

代码返回了 103 代表了canvas 指纹不对。

代码返回了101 代表了 en生成的值和 knock的值不对。

代码返回了104 代表了 轨迹的值不对。最终也是卡死在了这一步。
至于识别的话。这里我使用了CSDN的某位大佬的方案。
使用cv2 手动的去滑。然后 line 的去模拟轨迹。但是实际下来好像是不太行。
这里我把代码也开源出来
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| def record_trajectory(img_path):
points = []
img = cv2.imread(img_path)
if img is None:
print("无法加载图片,请检查路径")
return ""
cv2.namedWindow('Image Trajectory Recorder')
cv2.setMouseCallback('Image Trajectory Recorder',
lambda event, x, y, flags, param:
(points.append({'x': x, 'y': y, 'time': int(time.time() * 1000)}))
if event == cv2.EVENT_LBUTTONDOWN or (
event == cv2.EVENT_MOUSEMOVE and flags == cv2.EVENT_FLAG_LBUTTON) else None)
print("在图片上按住鼠标左键并移动来绘制轨迹,按's'保存并返回,按'q'退出")
while True:
clone = img.copy()
if len(points) > 1:
for i in range(len(points) - 1):
cv2.line(clone,
(points[i]['x'], points[i]['y']),
(points[i + 1]['x'], points[i + 1]['y']),
(0, 255, 0), 2)
cv2.imshow('Image Trajectory Recorder', clone)
key = cv2.waitKey(1) & 0xFF
if key == ord('s'):
if not points:
print("没有记录到轨迹点")
break
start_time = points[0]['time']
for point in points:
point['time'] = point['time'] - start_time
point['x'] += 30
point['y'] += 35
trajectory_data = json.dumps(points, indent=2)
print(f"轨迹已记录,共 {len(points)} 个点。")
cv2.destroyAllWindows()
return trajectory_data
elif key == ord('q'):
print("已退出,未保存轨迹")
break
cv2.destroyAllWindows()
return ""
|